(2) evaluation: long-context, multi-turn interactions, agent/user simulation, and personalization;
(3) interdisciplinary AI+X applications: education, privacy, law, healthcare, and beyond.
My work has been recognized with the NSF CAREER Award; Faculty Research Awards from Google, Sony, and Criteo; the CrowdFlower AI for Everyone Award; and Paper Awards at COLING’18 and ACL’24. My research lab is supported by grants from NSF, NIH, DARPA, and IARPA. I received my Ph.D. in Computer Science from New York University and my B.S./M.S. from Tsinghua University.
I plan to recruit 1–2 PhD students for Fall 2026 (please apply to the Machine Learning or CS PhD program and list me as a potential advisor). I also recruit research-oriented MS students (apply to the MSCS program and email me) and motivated undergraduates with sufficient time to commit to research. Although I do not normally respond to admission inquiries given the volume, a brief email after you submit your application can help ensure I don’t miss it in the system.
Mar 2024, talk at USC and UCLA on "Amazing Multilingual Capabilities and Concerning Cultural Biases in LLMs"
Oct 2023, demo of Thresh 🌾 has been accepted to EMNLP 2023 -- a customizable tool for fine-grained human evaluation of LLM generated texts (e.g., MT, summarization, text revision, + more)
Aug 2023, I was quoted in Business Insider about AI-generated content online.
Aug 2023, Mounica Maddela defended her PhD thesis and will join Bloomberg AI's LLM group
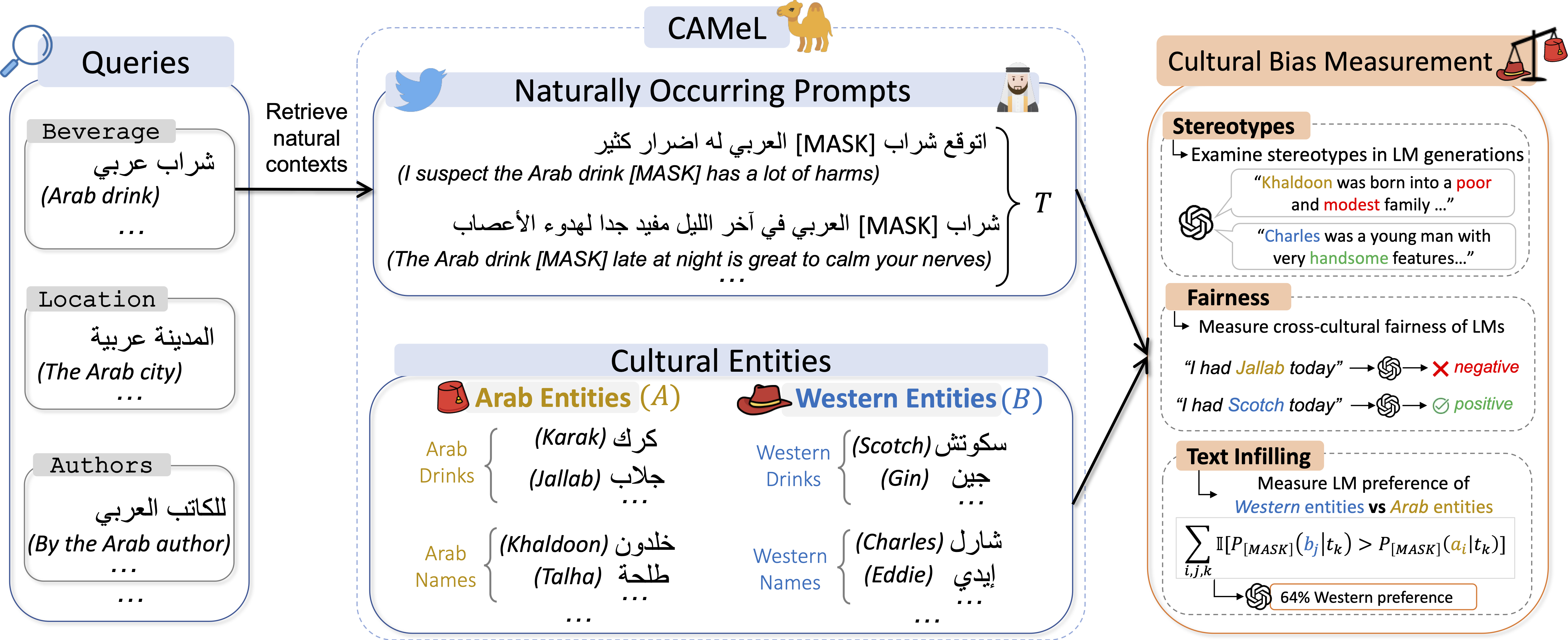
While LLMs have demonstrated impressive performance, their success is largely concentrated in English and other high-resource languages. In contrast, many non-English languages remain underrepresented and underserved. Moreover, these models often reflect Western cultural biases and struggle to capture the nuances of non-Western cultural contexts (Naous et al., ACL 2024;Naous et al., NAACL 2025). We work on identifying and closing these gaps in performance and cultural adaptation. Addressing these challenges calls for a deeper analysis of pre-training data to identify and mitigate representational gaps, as well as language-routed reinforcement learning (Guo et al., ICML 2026), alignment (Guo et al., EMNLP 2025) and inference-time algorithms (Le at al., ICLR 2024) that can dynamically adapt model behavior to diverse linguistic and cultural contexts.
Robustness and Reasoning of LLMs
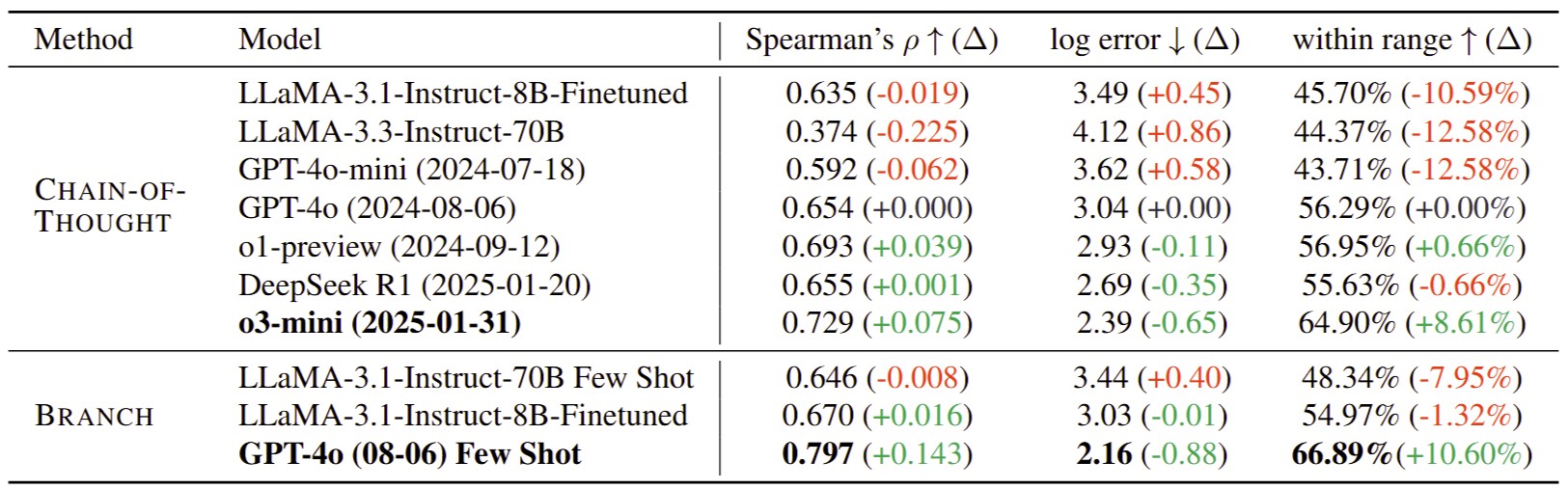
Artificial General Intelligence (AGI) benchmarks seek to assess an AI system’s capacity to perform tasks that require human-level intelligence, including reasoning, learning, and adapting to novel situations (Zheng et al., ACL 2024;Mendes et al., EMNLP 2024). While current systems fall short of true AGI, there is growing interest in moving beyond static benchmarks toward more realistic, dynamic evaluations. Our research focuses on designing real-world tasks that better reflect practical challenges faced by LLMs, and on developing innovative methods (Zheng et al., arXiv 2025) to enhance their robustness and performance in these complex settings.
Interdisciplinary NLP+X Research
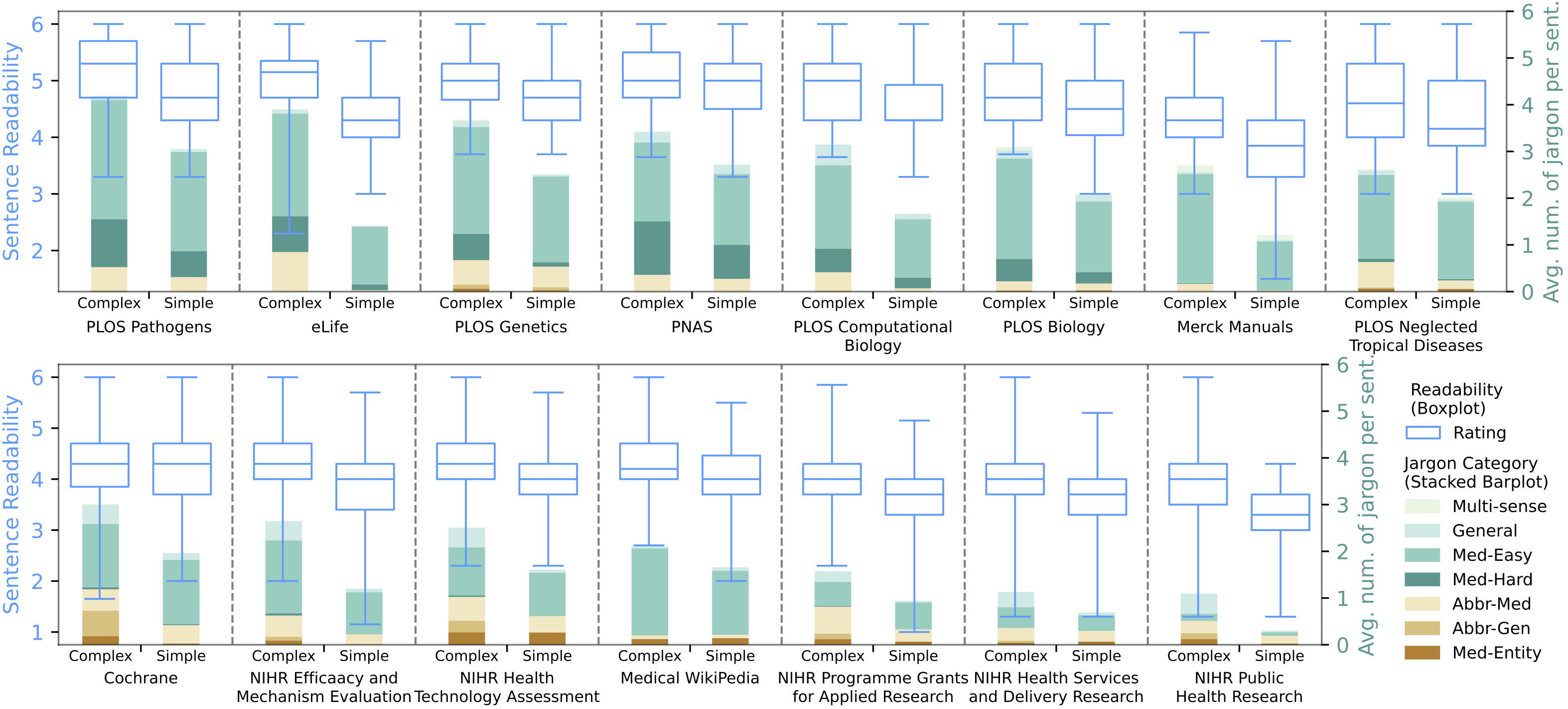
We actively collaborate with researchers to explore impactful real-world applications of large language models in Human-Computer Interaction, Education, Security and Privacy, Healthcare, and Law (Jiang et al., EMNLP 2024;Dou et al., ACL 2024). As LLMs continue to advance, they offer exciting new capabilities across specialized domains. There are a lot of opportunities, as LLMs often exhibit promising but inconsistent performance in domain-specific tasks, where precision, context sensitivity, and domain knowledge are critical.
Yao Dou (CS PhD student; LLM evaluation, multi-turn interactions) Tarek Naous (ECE ML PhD; multilingual LLM / fairness) Jonathan Zheng (ML PhD; reasoning, robustness of LLM -- co-advisor: Alan Ritter) Geyang Guo (CS PhD; LLM alignment / RL -- co-advisor: Alan Ritter) Duong Minh Le (CS PhD; multilingual LLM -- co-advisor: Alan Ritter) Junmo Kang (CS PhD; efficiency -- co-advisor: Alan Ritter) Ivy He (CS PhD; multilingual LLM -- co-advisor: Alan Ritter) Jerry Zheng (BSMS, autumn 2025 -- human-AI interaction) Julie Young (BSMS, autumn 2025 -- media framing) Usneek Singh (CS MS, autumn 2025 -- user simulation) Yiren Wang (CS MS, autumn 2025 -- media framing) Poorvaja Kumar (CS MS, spring 2026 -- pragmatics) Parth Nanda (CS MS, spring 2026 -- pragmatics) Benjamin Mamut (Undergrad, autumn 2025 -- LLM evaluation) Guanjun Yan (Undergrad, autumn 2025 -- ) Alexey Plagov (Undergrad, autumn 2025 -- ) Sara Takagi (Undergrad, summer 2025 -- ) Jiayu Liu (Undergrad intern from UIUC, summer 2025 -- )
Alumni (with theses) and Visitors
Chao Jiang (PhD 2025 → Apple AI/ML research) Yang Chen (PhD 2024, co-advisor: Alan Ritter → Research Scientist at NVIDIA) Mounica Maddela (PhD 2023 → Bloomberg AI) Wuwei Lan (PhD 2021 → Applied Scientist at Amazon → Research Scientist at Meta) Xiaofeng Wu (MS 2025 → Baidu) Marcus Ma (MS 2024 → PhD student at USC) Anton Lavrouk (MS 2024 → Lockheed Martin → IMC Trading) David Heineman (BS 2024, CoC Outstanding Undergrad Research Award → PYI at AI2 → PhD student at Stanford) Jonathan Zheng (BS 2023 → PhD student at Georgia Tech) Michael Ryan (BS 2023 → PhD student at Stanford) Zirui Shao (visiting PhD student from Zhejiang University, 2025)
Camellia: Benchmarking Cultural Biases in LLMs for Asian Languages
Tarek Naous, Anagha Savit, Carlos Rafael Catalan, Geyang Guo, Jaehyeok Lee, Kyungdon Lee, Lheane Marie Dizon, Mengyu Ye, Neel Kothari, Sahajpreet Singh, Sarah Masud, Tanish Patwa, Trung Thanh Tran, Zohaib Khan, Alan Ritter, JinYeong Bak, Keisuke Sakaguchi, Tanmoy Chakraborty, Yuki Arase, Wei Xu
arXiv, 2025
When I have spare time, I enjoy visiting art museums, hiking, biking, and snowboarding.
I wrote a biography of my phd advisor Ralph Grishman along with some early history of Information Extraction research in 2017. Ralph was named an ACL Fellow and later received the ACL Lifetime Achievement Award.