Source Code
It is written in Scala and can be found on the Github [code].Paper
Extracting
Lexically Divergent Paraphrases from Twitter
[pdf]
[bib]
Wei Xu, Alan Ritter, Chris Callison-Burch, William B. Dolan
and Yangfeng Ji
In Transactions of the Association for Computational Linguistics (TACL) 2014
Abstract
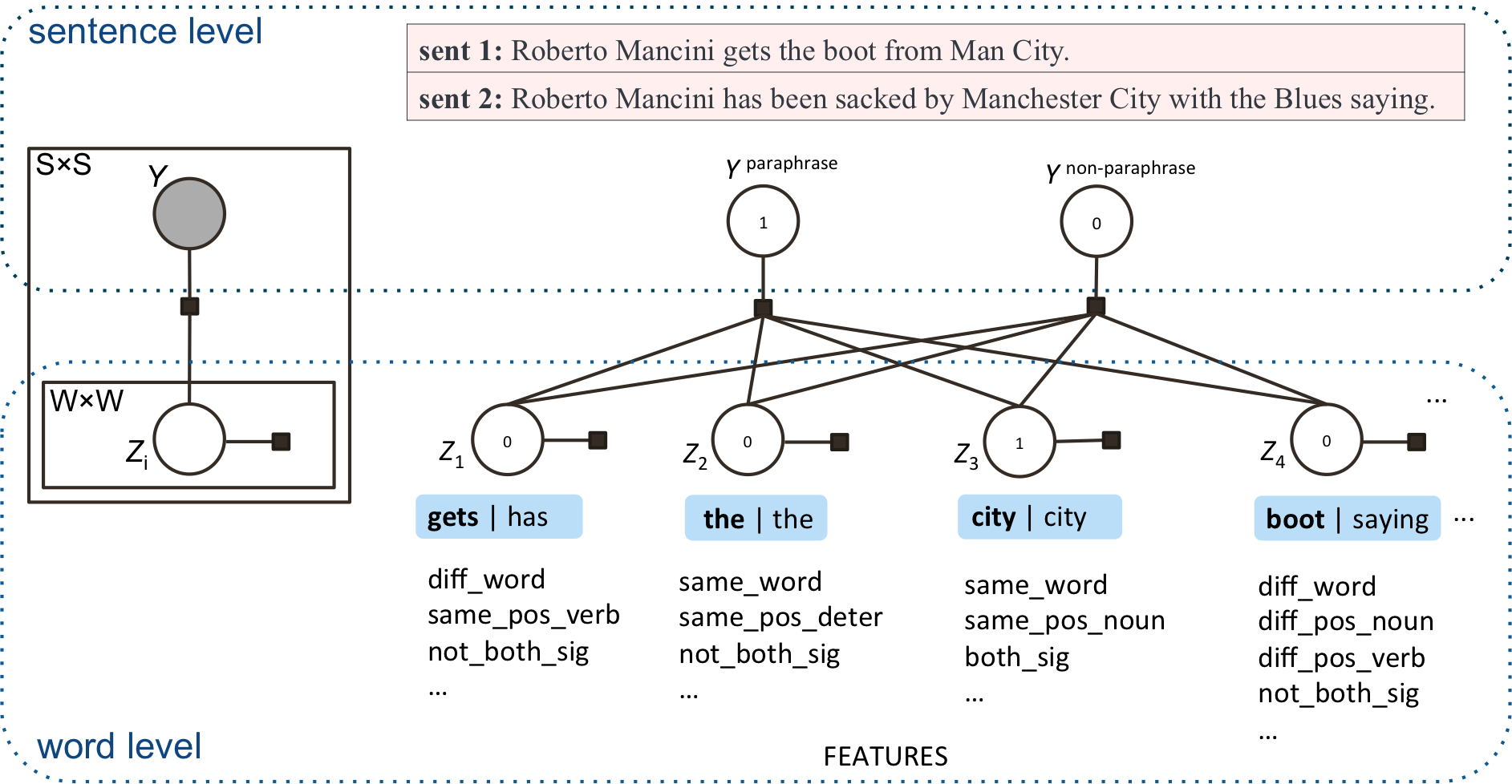
We present MULTIP (Multi-instance Learning Paraphrase Model), a new model suited to identify paraphrases within the short messages on Twitter. We jointly model paraphrase relations between word and sentence pairs and assume only sentence-level annotations during learning. Using this principled latent variable model alone, we achieve the performance competitive with a state-of-the-art method which combines a latent space model with a feature-based supervised classifier. Our model also captures lexically divergent paraphrases that differ from yet complement previous methods; combining our model with previous work significantly outperforms the state-of-the-art. In addition, we present a novel annotation methodology that has allowed us to crowdsource a paraphrase corpus from Twitter. We make this new dataset available to the research community.